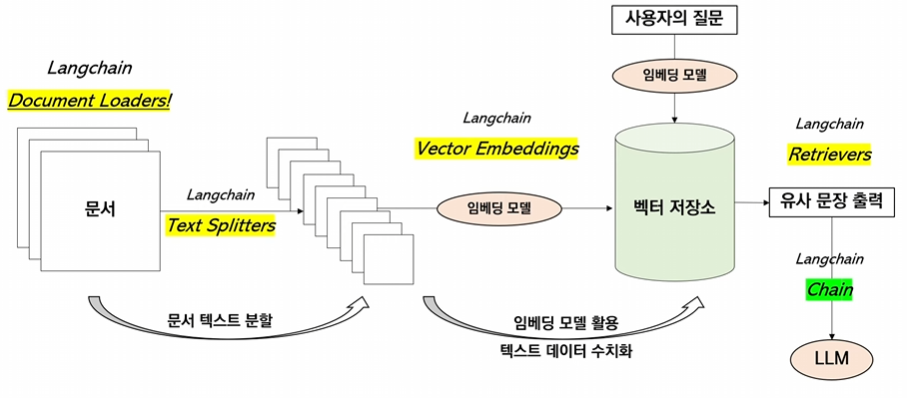
Text Splitter란?
토큰 제한이 있는 LLM이 여러 문장 혹은 문서를 참고해서 답변할 수 있게 문서를 분할하는 역할
위 그림에서 문서를 chunking하는 과정을 text splitters가 담당한다. 이후에는 chunk들을 임베딩 벡터로 만들고 벡터 스토어에 저장을 해준다.

이때 chunk 1개당 1개의 벡터가 매칭이 된다. 즉, vector store의 벡터들은 chunk들을 임베딩한 벡터들이다.
이렇게 chunk별로 임베딩을 하는 이유는 질문 임베딩과 유사도가 높은 벡터의 청크를 llm에 전달해서 사용자가 원하는 답을 얻게 하기 위해서이다.
근데 LLM은 토큰 제한이 있기 때문에 chunk 사이즈, 몇개의 chunk를 LLM에 전달할지 등을 고려해야한다.
Character Text Splitter vs Recursive Character Text Splitter
두가지 모두 특정한 구분자를 기준으로 chunk를 나누고 chunk들의 사이즈를 제한하는 기능이 있다.

Character Text Splitter
- 구분자 1개를 기준으로 문장을 구분
- 예를 들어, 줄바꿈이 2번 되면 chunk를 나눠라~ 라고 설정할 수 있다.
- 최대 토큰 개수를 설정할 수 있다.
- 구분자 1개를 기준으로 하기 때문에 max_token을 못지키는 경우도 존재
Recursive Character Text Splitter
- 구분자 여러 개(줄바꿈, 마침표, 쉼표 순으로)를 돌아가면서 재귀적으로 분할
- 첫번째 구분자로 분할하다 max_token을 못지키면 다음 구분자를 기준으로 분할
실습
with open("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/state_of_the_union.txt") as f:
state_of_the_union = f.read()
state_of_the_union!pip install langchainCharacterTextSplitter
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 1000,
chunk_overlap = 1000,
length_function = len,
)- separator : 구분자
- chunk_size : 크기
- chunk_overlap : chunk를 구분할때 그 이전 chunk의 일부를 포함해서 구분하게 하는 것. Overlap의 크기는 얼마나 중복해서 포함할지이다.
- length_function : chunk_size를 측정할때 저 수치(1000)이 무슨 기준인지 정의하는 것. len으로 하는 경우 글자수 기준이다.

texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
print("-"*100)
print(texts[1])
print("-"*100)
print(texts[2])char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i]))
print(char_list)text_splitter.create_documents([state_of_the_union])우리가 나눈걸 기준으로 document를 만들겠다 하면 create_documents로 document list로 만들 수 있다.
pdf 문서 나누기
!pip install pypdffrom langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()#load_and_split()으로 페이지 단위로 pdf를 분할len(pages)print(pages[1].page_content)Character Text Splitter로 나눠보기
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)#loader를 통해서 가져오면 document 객체가 만들어진다.
#따라서, split_documents를 통해서 나눠줘야한다.
texts = text_splitter.split_documents(pages)print(texts[1].page_content)RecursiveCharacterTextSplit
RecursiveCharacterTextSplit은 재귀적으로 문서를 분할합니다. 먼저,"\n\n"(줄바꿈)을 기준으로 문서를 분할하고 이렇게 나눈 청크가 여전히 너무 클 경우에"\n"(문장 단위)을 기준으로 문서를 분할합니다. 그렇게 했을 때에도 청크가 충분히 작아지지 않았다면 문장을 단어 단위로 자르게 되지만, 그렇게까지 세부적인 분할은 자주 필요하지 않습니다.
분할 구분자 순서 = ["\n\n", "\n", " ", ""]- 이런 식의 분할 방법은 문장들의 의미를 최대한 보존하는 형태로 분할할 수 있도록 만들고, 그렇기 때문에 다수의 청크를 LLM에 활용함에 있어서 맥락이 유지되도록 하기에 용이합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200,
length_function = len,
)texts = text_splitter.create_documents([state_of_the_union])
print(texts[0].page_content)
print("-"*500)
print(texts[1].page_content)char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()len(pages)print(pages[1].page_content)texts = text_splitter.split_documents(pages)#page 18개를 chunk 31개로 나눔
len(texts)print(texts[1].page_content)char_list = []
for i in range(len(texts)):
char_list.append(len(texts[i].page_content))
print(char_list)기타 splitter
일반적인 글로 된 문서는 모두 textsplitter로 분할할 수 있으며, 대부분의 경우가 커버된다. 그런데 코드, latex 등과 같이 컴퓨터 언어로 작성되는 문서의 경우 textsplitter로 처리할 수 없으며 해당 언어를 위해 특별하게 구분하는 splitter가 필요합니다. 예를 들어, Python 문서를 split하기 위해서는 def, class와 같이 하나의 단위로 묶이는 것을 기준으로 문서를 분할할 필요가 있습니다. 이러한 원리로 Latex, HTML, Code 등 다양한 문서도 분할 할 수 있습니다.
python 분할기
from langchain.text_splitter import(
RecursiveCharacterTextSplitter,
Language,
)RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language = Language.PYTHON, chunk_size = 50,chunk_overlap = 0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docspython 코드를 list형태로 create_documents에 넣으면 잘 분할해준다.
토큰 단위 분할기
텍스트 분할의 목적은 LLM이 소화할 수 있을 정도의 텍스트만 호출하도록 만드는 것입니다. 따라서 LLM이 소화할 수 있는 양으로 청크를 제한하는 것은 LLM 앱을 개발할 때 필수적인 과정입니다.
LLM은 텍스트를 받아들일 때, 정해진 토큰 이상으로 소화할 수 없게 설계되어 있습니다. 따라서 글을 토큰 단위로 분할한다면 최대한 많은 글을 포함하도록 청크를 분할할 수 있습니다.
토큰이라는 것은, 텍스트와 달리 Transformer에서 처리하는 방식에 따라서 그 수가 달라질 수 있습니다. 따라서, LLM 앱을 개발하고자 한다면 앱에 얹힐 LLM의 토큰 제한을 파악하고, 해당 LLM이 사용하는 Embedder를 기반으로 토큰 수를 계산해야 합니다. 예를 들어, OpenAI의 GPT 모델은 tiktoken이라는 토크나이저를 기반으로 텍스트를 토큰화합니다. 따라서 tiktoken encoder를 기반으로 텍스트를 토큰화하고, 토큰 수를 기준으로 텍스트를 분할하는 것이 프로덕트 개발의 필수 요소라고 할 수 있습니다.
!pip install tiktokenimport tiktoken
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)- get_encoding을 통해서 임베딩 모델 선언
- cl100k_base는 gpt 계열 모델들을 임베딩할때 사용되는 임베딩 모델.
tiktoken_len(texts[1].page_content)text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000, chunk_overlap=0,length_function=tiktoken_len
)
texts = text_splitter.split_documents(pages)- length_function을 tiktoken_len으로 설정해서 tiktoken 기준으로 토큰의 길이를 잰다.
- pages를 split_documents 함수를 통해서 나눈다.
print(len(texts[1].page_content))
print(tiktoken_len(texts[1].page_content))token_list = []
for i in range(len(texts)):
token_list.append(len(texts[i].page_content))
print(token_list)Reference
모두의 AI 유튜브 채널[https://www.youtube.com/@AI-km1yn]
'인공지능 > RAG' 카테고리의 다른 글
| LangChain (8) Retrieval - Vectorstores (0) | 2024.04.08 |
|---|---|
| LangChain (7) Retrieval - Text Embeddings (0) | 2024.04.08 |
| Knowledge Distillation (0) | 2024.04.06 |
| LangChain (5) Retrieval - Document Loaders (0) | 2024.03.23 |
| LangChain (4) Prompt Template (1) | 2024.03.23 |