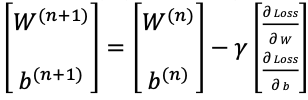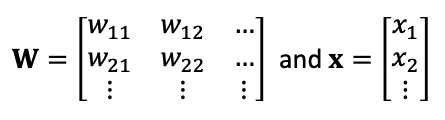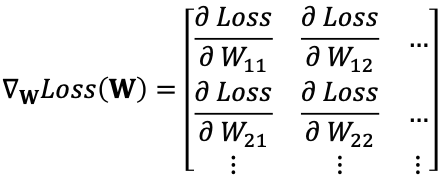KNN 알고리즘은 간단한 분류 알고리즘으로 거리에 따라 새로운 데이터의 class를 분류한다.
별 모양의 새로운 데이터가 들어오면 하이퍼파라미터 k를 기준으로 새로운 데이터에서 가장 가까운 k개의 데이터를 찾고 해당 데이터중에서 가장 많은 데이터를 가진 Class로 분류를 한다.
아래 그림의 경우에서 k = 3일때 3개의 데이터 중에서 class 1이 1개, class 2가 2개이므로 class 2로 분류한다.
반면에 k = 5일때 5개의 데이터 중에서 class 1이 3개, class 2가 2개이므로 class 1으로 분류한다.
KNN 알고리즘의 과정은 다음과 같다.
데이터를 분석하고
기존 데이터와 새로운 데이터의 거리를 계산
k개의 가장 가까운 샘플을 선정하고
가장 많은 class를 선정한다.
KNN 알고리즘에서 일반적으로 k값은 동률인 경우를 막기 위해서 홀수를 사용한다.
Decision boundary
Decision boundary란 두 개의 서로 다른 클래스의 기준이 되는 선이다. 하지만 decision boudary는 이상치(outlier)에 의해 이상한 부분에 존재할 수 있다.
이러한 것처럼 경계면을 부드럽게 만들기 위해서는 k의 값을 키우는 것이 하나의 방법이 될 수 있다.
k = 1로 하면 이론상 훈련 데이터에 완벽하게 동작한다. 하지만 실제 데이터에서는 아마 제대로 동작을 안할 것이다.
Train Test Split
따라서, 우리는 전체 훈련 데이터를 Train Validation Test 데이터로 나눠서 Train data로 훈련을 하고 validation으로 검증을 해서 hyperparameter 값을 최적화한다. 이 경우에는 k값을 수정한다. 이후에 Test data로 최종 검증을 한다.
Cross Validation
Cross validation은 전체 데이터에서 test 데이터를 제한 나머지를 fold로 나눈 후 학습시마다 각 fold를 돌아가면서 validation으로 사용하고 결과의 평균을 사용한다.
KNN 장단점
KNN의 장점은 모델 자체가 단순하는 것이다. 그리고 학습이 필요 없다. 왜냐하면 label 단 데이터만 있으면 되니까.
반대로 단점은 메모리를 많이 사용하고 연산이 많다는 점이다. 학습시마다 모든 데이터와 거리 계산이 필요하기 때문이다.
여기서 $\gamma_W$는 learning rate로 각 epoch마다 기울기를 얼마나 변화시킬지, 즉 밑에 나오는 그래프에서 얼마나 이동할지 거리를 결정하는 매개변수이다.
그리고 $-\frac{\delta_{Loss}}{\delta_{b}}$는 기울기와 반대방향으로 진행한다는 의미이다. 이게 무슨소리인가하면
위의 그림을 살펴보면 최소값으로 향하기 위해서는 기울기의 반대방향으로 진행해야한다.
기울기가 음인 경우에는 양의 방향으로 가야 극소점으로 이동한다.
기울기가 양인 경우에는 음의 방향으로 가야 극소점으로 이동한다.
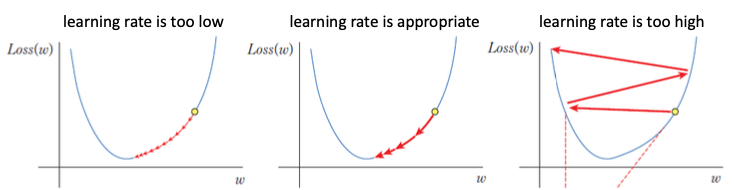
Learning rate
Learning rate에 대해 조금더 알아보면 lr이 너무 작으면 학습 속도가 느리고 너무 크면 최소점을 지나버린다.
따라서, 적절한 lr을 선택하는 것이 모델 훈련에 중요한 요소이다.
Local Minima
머신러닝 분야의 고질적인 문제인데 Loss Function을 평면이나 공간에 표현했을때 여러개의 극소점이 존재하게 되는데 그 중에서 전역적으로 최소인 점은 1개이다. 하지만 모델이 학습과정에서 위의 파란 선과같은 과정을 통해 지역국소점에 빠지게 되면 이를 빠져나올 방법이 사실 없다. 왜냐하면 복잡한 모델의 경우 위 그림처럼 나타내는것 자체가 불가능하기 때문이다.
아래는 GD 식이다.
GD 병렬 계산
GD를 계산할때 W, b를 아래와 같이 병렬적으로 계산할 수 있다.
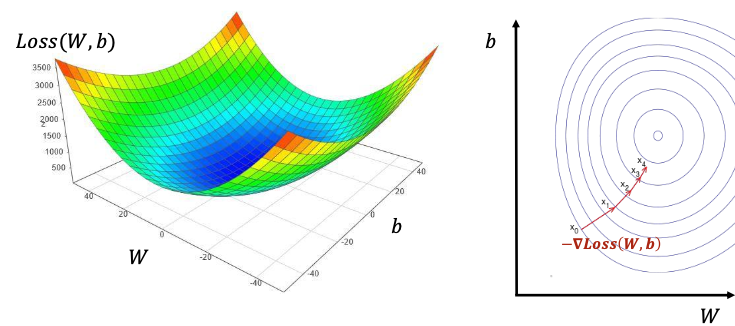
Loss(W,b)에 대해서 기울기 값 Gradient는 아래와 같이 표현한다.
높은 차원의 Loss(W,b)에 대해서도 GD로 동일하게 계산한다.
오른쪽은 W,b에 대해서 그린 등고선이다. 최솟값은 가운데 점이므로 기울기의 반대 방향을 따라서 가운데 점으로 이동한다.
가중치가 여러 개인 일반적인 경우 $f(x)=Wx$ 식이 있을때 가중치 W와 x는 아래와 같은 행렬이다.
그리고 Gradient Descent 값은 $$ W^{(n+1)}=W^{(n)}-\gamma \Delta_{W} Loss(W^{(n)}) $$
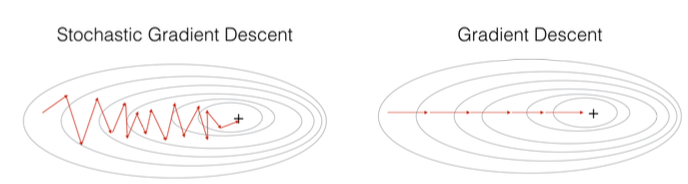
Stochastic Gradient Descent
기존의 GD는 Loss Function의 값을 구할때 모든 데이터에 대해서 Loss값을 구한후 다 더해서 데이터의 총 수로 나눠줬다.
하지만 이러한 방식은 계산량이 많고 오래 걸린다.
전체 데이터셋에 대해서 Gradient를 평가하는 기존 방식에서 벗어나서 SGD는 데이터를 여러 개의 부분집합(mini-batch)으로 나누고 gradient를 계산하고 가중치를 업데이트한다.
SGD는 GD에 비해 연산량이 적고 빠르지만 더 "oscillate" 또는 "진동"한다. 진동한다는 의미는 목적지를 향해 갈때 좌우로 더 움직이는 것을 뜻한다.
그리고 이러한 데이터를 평면에 찍어서 도식화하면 아래와 같이 한 이미지데이터는 한 데이터 포인트에 표시할 수 있고 이를 통해 데이터의 분포를 확인할 수 있다. (물론, 7500차원의 이미지를 2차원 평면에 위치시킬 수는 없다. 해당 이미지는 이해를 돕기 위한 이미지일 뿐이다.)
Linear Method
앞서 계속 설명한 ML 모델 또는 함수 f(x)를 찾는 것은 매우 어렵다. 따라서 사람들은 우선 f(x)를 특정 form 내지는 frame으로 설정했다. 이중 한 방법이 바로 Linear method이다.
Linear Method는 단순하게 함수를 $f(x)=wx+b$와 같이 직선으로 표현하는 방식을 의미한다. 이를 통해 데이터셋에 가장 적합한 w, b를 찾으면 된다.
Regression vs Classification
위 이미지와 같이 Regression(회귀)는 추세를 찾는 것이고 Classification(분류)는 기준을 잡아서 데이터를 몇 가지로 나누는 것이다. 예를 들어, 주가를 예측하거나 집값을 예측하는 모델은 회귀 모델이고 사과와 배를 찾는 모델은 분류 모델이다.
Linear Regression
회귀란 데이터를 2D나 더 높은 차원의 공간에서 가장 잘 표현하는 직선이나 곡선을 찾는 것이다.
회귀중에서 선형 회귀는 직선을 찾는 과정이다. 좀더 구체적으로는 $f(x)=wx+b$ 라는 함수에서 기울기 w와 절편 b를 구하는 것이다. 여기서 w와 b를 일반적으로 매개변수 or parameter라고 한다.
따라서, 학습 시에 input은 학습 데이터가 되고 검증시에는 input은 우리가 답을 찾기를 원하는 데이터가 된다 → 여기서 답은 우리가 원하는 Task에 따라 조금씩 달라진다.
Machine Learning Tasks
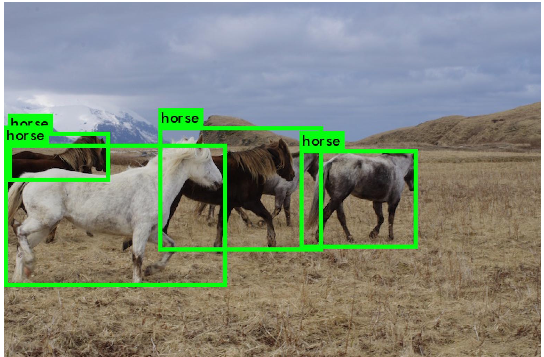
Object Detection
말그대로 객체 탐지이다. 사진에서 객체를 탐지해서 bounding box로 감싼다. 이때 image를 ML 모델에 넣어주면 ML 모델은 object label과 Bounding box를 계산한다.
Sementic segmentation
Sementic segmentation은 단위별로 색칠을 하는 것으로 사진에서 물체의 테두리를 기준으로 표시를 하는 Task이다. Input으로 image를 주면 ML 모델은 픽셀 단위로 구분해서 label을 달아준다.
Image to Caption
Input으로 image를 주면 우선 CNN(convolutional neural network)로 feature를 추출하고 해당 feature를 바탕으로 LM(언어 모델) 여기서는 RNN이 caption 혹은 설명을 생성한다.
Caption to Image
Image to Caption과는 반대로 Input으로 caption을 주면 이미지를 생성해낸다.
Machine Translation
기계번역은 한 언어를 다른 언어로 번역하는 Task로 NLP(자연어 처리) 분야에서 main task중 하나입니다.
Autonomous Driving
자율주행은 카메라 정보, 속도, 라이다 정보등이 입력되면 ML 모델이 자율적으로 주행을 하는 것이다.
기타 Task
3D pose for Furniture, Human pose, Visual Question Answering(VQA),
Machine Learning의 목표
ML의 목표는 f(x)를 최대한 현실에 가깝게 근사하는 것이다. 즉, 정확도가 높은 함수 f(x)를 만드는 것이다. 사실 웬만한 경우 x, y값은 존재한다. 예를 들어, 암진단하는 ML 모델을 훈련할때 암 영상과 label(정답)은 이미 존재한다. 하지만 진짜 어려운 부분은 f(x)를 만드는 것이다.
그렇다면 두가지를 해결해야한다. (1) 이 함수를 어떻게 구할지 (2) 현실의 문제를 어떻게 공식화 또는 함수화 할지
차원이 없는 값은 스칼라, 1차원 값은 벡터이다. 행렬은 모두가 알다시피 [1,2,3] 이런 값이다. 즉. 2차원으로 구성된 값을 행렬이라 한다. 이제 그 값들이 3차원으로 넘어가게 되면 그것을 Tensor(텐서)라고 부르게 된다. 그런데 컴퓨터 공학에서는 벡터를 1차원 텐서, 행렬을 2차원 텐서등으로 표현한다.
차원의 개념을 이해할때 1차원은 방, 2차원은 층, 3차원은 아파트 동, 4차원은 아파트 단지.
나는 이런 식으로 이해를 했다.
2차원 텐서 표현
그리고 2차원 텐서를 표현할때 행의 개수는 batch size, 열의 개수는 dimension으로 표기한다. 그 이유는 모델에 들어갈때 batch 단위로 들어가는데 이때 행 마다 들어가므로 batch size, 그리고 들어가는 입력의 길이 혹은 크기를 dimension이라고 하기 때문이다.
예를 들어 데이터가 6400개 있고, 각 데이터 하나의 크기가 64라고 하면 데이터의 차원은 64차원이고 전체 데이터셋의 크기는 6400 x 64이다. 하지만 모델이 데이터를 처리하는 기준은 batch size이다. batch size는 한번에 들어가는 데이터의 개수라고 생각하면 된다. 따라서, batch size가 64이면 64 x 64 의 데이터가 들어가고 이 과정을 100번 반복하게된다.
비전 분야의 3차원 텐서
이미지 데이터의 경우 RGB 값이 있고 각각의 영역이 2차원이므로 총 3차원이 된다. 여기서 이미지 데이터를 여러 장 사용하는 경우 3차원 데이터가 여러 개이므로 4차원 데이터가 된다. 이 경우 (batch size / # of images, width, height, channel)이 된다.
자연어 처리 분야의 3차원 텐서
자연어 처리 분야에서 3차원 텐서의 각 요소는 batch size, 문장 길이, 단어 벡터의 차원이 된다. 즉, (batch size, length, dimension)이 된다.
3D 텐서 예시
[[아 배고파 밥 줘] [집가서 빨리 게임하고 싶다] [운동해야 하는데 시간이 없다]]
컴퓨터는 이러한 데이터를 처리할때 단어가 몇개인지 알 수가 없다. 이를 컴퓨터가 처리할 수 있도록 하는 과정이 필요하다. 우선 단어별로 나눠준다.
오늘은 Linear Regression 문제에서 Gradient descent를 직접 구현해보자
데이터셋 로드
오늘의 데이터셋은 사이킷런의 당뇨병 데이터셋이다
총 10가지의 feature 열이 있는데 그중에서 bmi만을 가지고 실습을 진행한다.
아래의 코드를 통해 데이터셋을 로드하고 훈련 데이터셋과 테스트 데이터셋으로 나눈다.
import matplotlib.pylab as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import datasets
# Load the diabetes dataset.
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
# Select only one feature (BMI) and make into a 2-D array. The index of BMI feature is 2.
diabetes_X_new = diabetes_X[:, np.newaxis, 2]
# Separate training data from test data.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(diabetes_X_new, diabetes_y, test_size=0.1, random_state=0)
Gradient Descent 식
참고로 Gradient Descent의 식은 다음과 같다. $$W^{n+1} = W^n - r_{W} \frac{\delta_{Loss}}{\delta_{W}} $$
그리고 Loss 값을 구하는 식은 다음과 같다. $$ (y-f(x))^2 $$ $$ Loss(W,b) = \sum (y-f(x))^2 $$
따라서 우리는 Loss 식을 각각 W, b에 대해 편미분을 하고 GD 식에 적용하면 된다. 이제 코드로 구현해보자
코드 구현
# Train W and b using the training data only
# Use X_train and y_train only
W = np.random.rand() # Initialization of W
b = np.random.rand() # Initialization of b
epochs = 25000 # number of epochs
n = float(len(X_train)) # number of training samples
lr = 0.1 # learning rate
train_loss = []
for k in range(epochs):
y_pred = W * X_train + b
loss = np.square(y_train-y_pred)
loss = loss / n
train_loss.append(np.sum(loss))
dW = (-1/n) * np.sum((y_train-y_pred) * X_train)
db = (-1/n) * np.sum(y_train-y_pred) / n
W = W - lr * dW
b = b - lr * db
위 코드를 실행하면 상당히 빠른 시간안에 25000번의 epoch을 돌고 W,b를 구한다. 그 값을 확인해보자
print("Trained parameters")
print("W:", W,", b:", b)
이제 훈련데이터의 데이터 포인트와 우리의 Linear Regression 함수를 좌표계에 시각화하자
# Checking for traing: Using training data
# use X_train and y_train
y_pred = W*X_train + b
plt.scatter(X_train, y_train, color='black')
plt.plot(X_train,y_pred, color='blue', linewidth=3)
plt.title("Linear Regression Training Results")
plt.show()
테스트 데이터의 데이터 포인트로 시각화를 한다.
# Prediction: Using only the test data
# use X_test and y test only
y_pred = W*X_test + b
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test,y_pred, color='blue', linewidth=3)
plt.title("Linear Regression Test")
plt.show()
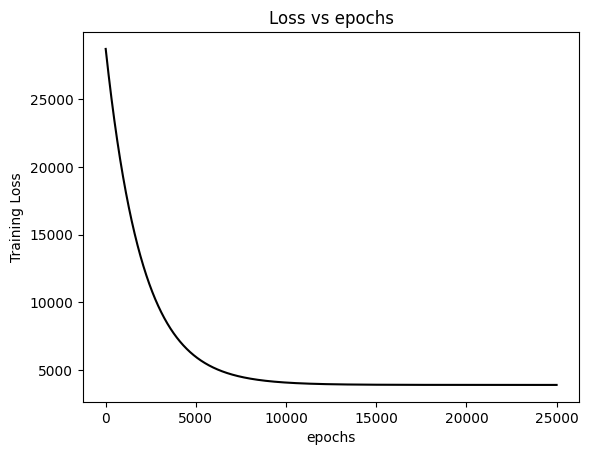
이제 train loss값을 시각화하자. 에폭이 지나면서 추이를 살피면 학습이 잘 되는지 파악할 수 있다. 우하향하여 진동 없이 수렴하면 베스트
# Display the loss at every epoch (sum of squares error on your training data)
plt.plot(np.arange(epochs), train_loss, color='black')
plt.title("Loss vs epochs")
plt.xlabel("epochs")
plt.ylabel("Training Loss")
plt.show()
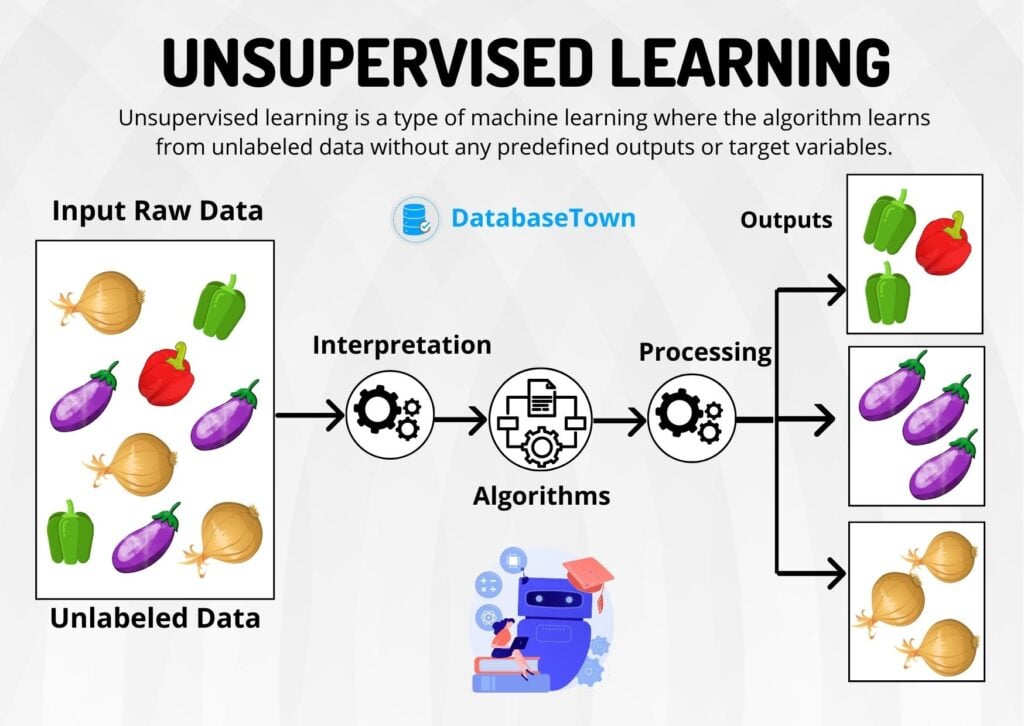
레이블이 없는 데이터셋을 그룹화하는 것을 클러스터링이라고 한다. 만약 레이블이 있는 데이터셋을 그룹화한다면 지도학습의 일종인 분류가 된다. 데이터셋을 그룹화하려면 유사한것들끼리 묶어야한다. 이를 위해 데이터셋의 특성 데이터를 유사성 측정이라는 측정 항목을 사용으로 결합해서 데이터들 간의 유사성을 측정할 수 있다.
클러스터링의 사용 예시
시장 세분화, 소셜 네트워크 분석, 검색결과 그룹화, 의료영상, 이미지 세분화, 이상 감지
클러스터링을 하면 각 클러스터에 클러스터 ID 라는 번호가 할당된다. 클러스터 ID가 할당되면 예시용 전체 특성 세트를 클러스터 ID로 압축할 수 있다. 이를 통해 복잡한 예를 간단한 클러스터 ID로 표현하면 클러스터링이 강력해진다. 대규모 데이터셋의 처리를 간소화할수있다. 클러스터링 출력은 다운스트림 ML 시스템의 특성 데이터 역할을 합니다.
일반화
클러스터의 일부 예시에 특성 데이터가 누락된 경우 클러스터의 다른 예시에서 누락된 데이터를 추론할 수 있다.
데이터 압축
클러스터의 모든 예시에 대한 특성 데이터는 클러스터 ID로 대체할 수 있다. 이 과정을 거치면 대체로 특성 데이터가 간소화되고 저장장소가 절약된다. 데이터셋의 규모가 커지면 커질수록 이러한 이점들이 두드러진다. 또한, 머신러닝 입력 데이터로 전체 특성 데이터셋 대신에 클러스터터 ID를 사용할수있다.
개인정보 보호
사용자를 클러스터링하고 사용자 데이터를 특정 사용자 대신 클러스터 ID와 매칭해서 개인 정보를 보존할 수 있다. 사용자 데이터로 사용자를 특정할 수 없도록 클러스터는 충분한 수의 사용자를 그룹화해야한다.
2) 차원 축소(Dimension reduction)
차원 축소란 머신러닝이나 통계분야에서 활용되는 기술로 문제의 무작위 변수(random variable)의 규모를 줄여서 주요한 변수의 집합을 구하는 것이다. 차원 축소는 두 과정으로 이루어지는데 첫 번째는 변수 선택(feature selection)과 변수 추출(feature extraction)이다. 변수 선택 과정에서는 모델을 대표할 다차원 데이터의 집합에서 특성들의 작은 부분집합들을 필터링, 임베딩, wrapping을 통해 선택한다. 변수 추출 과정에서는 데이터셋의 차원을 줄여서 변수를 모델화하고 구성 요소들에 대한 분석을 수행한다.
Machine Learning 과정에서 Best Feature Subset 을 주는 것이 아니라, 사용자에게 feature-rank를 줌으로 각 feature의 영향력을 알려주는 방법이다. 따라서 해당 모델에 Best Feature Subset 은 아닐 수 있더라도, 도움이 된다고 볼 수 있다. 또한 여기서 각 ranking 화 한 Feature 들은 독립변수로 본다.
Wrapper Method
Machine Learning의 예측 정확도 측면에서 가장 좋은 성능을 보이는 Subset을 뽑아내는 방법이다. Machine Learning 을 진행하면서 Best Feature Subset을 찾아가는 방법이기 때문에 시간과 비용이 매우 높게 발생한다. 하지만 최종적으로 Best Feature Subset을 찾아주기 때문에 모델의 성능을 위해서는 적절하다. 물론, 해당 모델의 파라미터와 알고리즘 자체는 완성도가 높아야 제대로 된 Best Feature Subset을 찾을 수 있다.
Forward Selection(전진 선택) : 변수가 없는 상태로 시작하며 반복할 때마다 가장 중요한 변수를 추가하여 더 이상 성능의 향상이 없을 때까지 변수를 추가한다.
Backward Elimination(후방 제거) : 모든 변수를 가지고 시작하며, 가장 덜 중요한 변수를 하나씩 제거하면서 모델의 성능을 향상시킨다. 더 이상 성능의 향상이 없을 때까지 반복한다.
Stepwise Selection(단계별 선택): Foward Selection 과 Backward Elimination 을 결합하여 사용하는 방식으로, 모든 변수를 가지고 시작하여 가장 도움이 되지 않는 변수를 삭제하거나, 모델에서 빠져있는 변수 중에서 가장 중요한 변수를 추가하는 방법이다. 이와 같이 변수를 추가 또는 삭제를 반복한다. 반대로 아무것도 없는 모델에서 출발해 변수를 추가, 삭제를 반복할 수도 있다.
1-2 K-Means
가장 고전적이면서 직관적으로 이해하기 쉬운 군집화 기법입니다. K-Means는 다음과 같은 과정을 통해 군집화가 이루어져요!
임의의 중심점 설정
처음엔 임의의 장소에 사전에 설정해준 군집의 수(k)만큼의 중심점을 배치해줍니다. 그리고 일단 가장 기본적으로 이 중심점을 기준으로 데이터들을 군집화 하게 됩니다.
위쪽에 있는 초록색 중심점과 가까운 데이터들은 초록 중심점 소속으로,
아래에 있는 노란색 중심점과 가까운 데이터들은 노랑 중심점 소속으로
각각 구분이 된다는 것이죠.
그러나 저 중심점의 위치가 과연 정말 최적의 위치일까요? 데이터들을 좀 더 잘 구분하려면 *"중심이 데이터들의 가운데"* 에 있어야 합니다.
가운데로 가기 위해서, 중심점은 데이터와 본인과의 거리를 계산하면서 점점 데이터의 중심으로 이동하기 시작합니다.
평균의 중심으로 중심점 이동
각 데이터와 중심점간의 거리를 나타낸 그림입니다. 이 중심점까지의 거리가 평균적으로 비슷할 때까지 중심점을 이동시키는 것이죠.
중심점이 이동되면, 이동한 중심점에 대해 데이터들의 소속 또한 다시 새롭게 정의됩니다. 지금의 그림에선 나타나지 않지만, 이동하기 전에는 초록색 중심점 소속이었지만, 이동하고 나서는 노란색 중심점 소속일 수도 있다는 것이죠.
보시면 초록색 점이 그나마 데이터들의 중심으로 이동했습니다. 이런 식으로 계속해서 중심점을 이동시킵니다.
중심점 확정 및 최종 군집화
위와 같은 방법으로 중심점은 계속 반복해서 이동합니다. 언제까지 이동하냐구요? 이동해도 그 위치일때까지요!
중심점을 이동하다보면,,
이렇게 거리를 계산해서 이동시켜도 더 이상 움직이지 않는 순간이 생깁니다.
이 순간의 중심점을 최종 중심점으로 잡고, 그 순간의 데이터들의 소속 또한 최종 소속으로 잡는 것이죠. 이렇게 군집화가 이루어집니다.
그럼 우리가 원했던 군집화가 이루어지는 것이죠.
문제
아래의 baseline코드에 비어있는 부분에 적절한 코드를 넣어 완성해주세요.
군집화 알고리즘은 KMeans로, 군집의 수는 3개로, random_state는 42로 지정해주세요!
KMeans 함수의 파라미터중 n_clusters 는 군집의 개수를 정해주는 옵션이고, random_state를 통해서 난수를 고정할 수 있다. 이후 make_blobs로 가상의 데이터를 만들고 X, y에 데이터를 로드한다. 독립변수의 수가 두개이므로 생성한 데이터프레임의 칼럼값은 x1, x2로 정한다. 데이터 프레임의 레이블값으로 make_blobs로 로드한 y를 추가한다. 여기서 y값은 클러스터의 종류를 표현하는 일종의 레이블이다. Numpy의 unique 메서드로 target_list를 선언했다. for문을 이용해서 target_cl이란 데이터 프레임을 새로 선언하고 산점도 그래프로 출력했다.
kmeans.label_ : 각 데이터가 어떤 클러스터에 속하는지 그 결과를 표현한다. cluster_centers_ : 학습된 kmeans 모델은 centroids(군집의 중심점)을 갖는다. 이를 수치적으로 출력하기 위해서 위 함수로 좌표값을 확인할 수 있다.
1-3 실루엣 계수
문제
위에서 형성한 k-means 기반 군집의 실루엣 계수를 측정해주세요!
**from** sklearn.metrics **import** silhouette_score, silhouette_samples
*## 각 데이터별 실루엣 점수*samples **=** ```!!HERE YOUR CODE!!
df['silhouette'] = samples
전체 실루엣 점수
score = !!HERE YOUR CODE!!
print(f"🚀전체 실루엣 점수🚀\n{score:.2f}\n")
print("📃군집별 평균 실루엣 점수📃")
print(df.groupby('clusters')['silhouette'].mean())
검색 힌트: sklearn silhouette_score, sklearn silhouette_samples
레이블이 없는 데이터셋을 그룹화하는 것을 클러스터링이라고 한다. 만약 레이블이 있는 데이터셋을 그룹화한다면 지도학습의 일종인 분류가 된다. 데이터셋을 그룹화하려면 유사한것들끼리 묶어야한다. 이를 위해 데이터셋의 특성 데이터를 유사성 측정이라는 측정 항목을 사용으로 결합해서 데이터들 간의 유사성을 측정할 수 있다.
클러스터링의 사용 예시
시장 세분화, 소셜 네트워크 분석, 검색결과 그룹화, 의료영상, 이미지 세분화, 이상 감지
클러스터링을 하면 각 클러스터에 클러스터 ID 라는 번호가 할당된다. 클러스터 ID가 할당되면 예시용 전체 특성 세트를 클러스터 ID로 압축할 수 있다. 이를 통해 복잡한 예를 간단한 클러스터 ID로 표현하면 클러스터링이 강력해진다. 대규모 데이터셋의 처리를 간소화할수있다. 클러스터링 출력은 다운스트림 ML 시스템의 특성 데이터 역할을 합니다.
일반화
클러스터의 일부 예시에 특성 데이터가 누락된 경우 클러스터의 다른 예시에서 누락된 데이터를 추론할 수 있다.
데이터 압축
클러스터의 모든 예시에 대한 특성 데이터는 클러스터 ID로 대체할 수 있다. 이 과정을 거치면 대체로 특성 데이터가 간소화되고 저장장소가 절약된다. 데이터셋의 규모가 커지면 커질수록 이러한 이점들이 두드러진다. 또한, 머신러닝 입력 데이터로 전체 특성 데이터셋 대신에 클러스터터 ID를 사용할수있다.
개인정보 보호
사용자를 클러스터링하고 사용자 데이터를 특정 사용자 대신 클러스터 ID와 매칭해서 개인 정보를 보존할 수 있다. 사용자 데이터로 사용자를 특정할 수 없도록 클러스터는 충분한 수의 사용자를 그룹화해야한다.
2) 차원 축소(Dimension reduction)
차원 축소란 머신러닝이나 통계분야에서 활용되는 기술로 문제의 무작위 변수(random variable)의 규모를 줄여서 주요한 변수의 집합을 구하는 것이다. 차원 축소는 두 과정으로 이루어지는데 첫 번째는 변수 선택(feature selection)과 변수 추출(feature extraction)이다. 변수 선택 과정에서는 모델을 대표할 다차원 데이터의 집합에서 특성들의 작은 부분집합들을 필터링, 임베딩, wrapping을 통해 선택한다. 변수 추출 과정에서는 데이터셋의 차원을 줄여서 변수를 모델화하고 구성 요소들에 대한 분석을 수행한다.
Machine Learning 과정에서 Best Feature Subset 을 주는 것이 아니라, 사용자에게 feature-rank를 줌으로 각 feature의 영향력을 알려주는 방법이다. 따라서 해당 모델에 Best Feature Subset 은 아닐 수 있더라도, 도움이 된다고 볼 수 있다. 또한 여기서 각 ranking 화 한 Feature 들은 독립변수로 본다.
Wrapper Method
Machine Learning의 예측 정확도 측면에서 가장 좋은 성능을 보이는 Subset을 뽑아내는 방법이다. Machine Learning 을 진행하면서 Best Feature Subset을 찾아가는 방법이기 때문에 시간과 비용이 매우 높게 발생한다. 하지만 최종적으로 Best Feature Subset을 찾아주기 때문에 모델의 성능을 위해서는 적절하다. 물론, 해당 모델의 파라미터와 알고리즘 자체는 완성도가 높아야 제대로 된 Best Feature Subset을 찾을 수 있다.
Forward Selection(전진 선택) : 변수가 없는 상태로 시작하며 반복할 때마다 가장 중요한 변수를 추가하여 더 이상 성능의 향상이 없을 때까지 변수를 추가한다.
Backward Elimination(후방 제거) : 모든 변수를 가지고 시작하며, 가장 덜 중요한 변수를 하나씩 제거하면서 모델의 성능을 향상시킨다. 더 이상 성능의 향상이 없을 때까지 반복한다.
Stepwise Selection(단계별 선택): Foward Selection 과 Backward Elimination 을 결합하여 사용하는 방식으로, 모든 변수를 가지고 시작하여 가장 도움이 되지 않는 변수를 삭제하거나, 모델에서 빠져있는 변수 중에서 가장 중요한 변수를 추가하는 방법이다. 이와 같이 변수를 추가 또는 삭제를 반복한다. 반대로 아무것도 없는 모델에서 출발해 변수를 추가, 삭제를 반복할 수도 있다.
1-2 K-Means
가장 고전적이면서 직관적으로 이해하기 쉬운 군집화 기법입니다. K-Means는 다음과 같은 과정을 통해 군집화가 이루어져요!
임의의 중심점 설정
처음엔 임의의 장소에 사전에 설정해준 군집의 수(k)만큼의 중심점을 배치해줍니다. 그리고 일단 가장 기본적으로 이 중심점을 기준으로 데이터들을 군집화 하게 됩니다.
위쪽에 있는 초록색 중심점과 가까운 데이터들은 초록 중심점 소속으로,
아래에 있는 노란색 중심점과 가까운 데이터들은 노랑 중심점 소속으로
각각 구분이 된다는 것이죠.
그러나 저 중심점의 위치가 과연 정말 최적의 위치일까요? 데이터들을 좀 더 잘 구분하려면 *"중심이 데이터들의 가운데"* 에 있어야 합니다.
가운데로 가기 위해서, 중심점은 데이터와 본인과의 거리를 계산하면서 점점 데이터의 중심으로 이동하기 시작합니다.
평균의 중심으로 중심점 이동
각 데이터와 중심점간의 거리를 나타낸 그림입니다. 이 중심점까지의 거리가 평균적으로 비슷할 때까지 중심점을 이동시키는 것이죠.
중심점이 이동되면, 이동한 중심점에 대해 데이터들의 소속 또한 다시 새롭게 정의됩니다. 지금의 그림에선 나타나지 않지만, 이동하기 전에는 초록색 중심점 소속이었지만, 이동하고 나서는 노란색 중심점 소속일 수도 있다는 것이죠.
보시면 초록색 점이 그나마 데이터들의 중심으로 이동했습니다. 이런 식으로 계속해서 중심점을 이동시킵니다.
중심점 확정 및 최종 군집화
위와 같은 방법으로 중심점은 계속 반복해서 이동합니다. 언제까지 이동하냐구요? 이동해도 그 위치일때까지요!
중심점을 이동하다보면,,
이렇게 거리를 계산해서 이동시켜도 더 이상 움직이지 않는 순간이 생깁니다.
이 순간의 중심점을 최종 중심점으로 잡고, 그 순간의 데이터들의 소속 또한 최종 소속으로 잡는 것이죠. 이렇게 군집화가 이루어집니다.
그럼 우리가 원했던 군집화가 이루어지는 것이죠.
1-3 실루엣 계수
위에서 우리는 군집이 잘 형성되었는지 groupby와 시각화를 통해 확인했습니다. 과연 이 방법이 최선일까요?? 우리가 분류와 회귀에서 metric을 통해 모델의 성능을 측정했던 것처럼, 얼마나 잘 묶였는지를 측정하는 지표는 없을까요?🤔
실루엣 계수를 소개합니다. 실루엣 계수는 쉽게 말씀드리면
군집 내의 데이터끼리는 얼마나 잘 뭉쳐있는지, 다른 군집의 데이터와는 얼마나 멀리 떨어져 있는지
를 측정한 지표라고 생각하시면 됩니다.
측정하는 방법을 간단하게 말씀드릴게요!
저기서 초록색으로 표시된 데이터를 i번째 데이터라고 했을 때,
같은 초록색 군집에 속해있는 데이터들과 i번째 데이터와의 거리의 평균을 a(i) 라고 하고,
주황색 군집에 속해있는 다른 데이터들과의 거리의 평균을 b(i) 라고 하는 것이죠.
그럼 직관적으로 "군집내부 데이터끼리 얼마나 잘 뭉쳐져있고, 다른 군집의 데이터와는 얼마나 잘 떨어져있는지"를 나타낼 수 있게 되는 것입니다!
이렇게 나온 실루엣 계수(Silhouette Coefficient)는 -1~1 사이의 값을 가집니다. (정규화 과정을 거쳐서 그래요!)
1일 수록 좋지 않은 것이며, 1일 수록 군집화가 잘 수행된 것입니다.
0이 서로 다른 군집끼리 가까운 것을 의미하는데, 실루엣 계수가 -값을 가진다는 것은.. 군집끼리 서로 영켜있다~~ 라는 말이 되겠죠. 상당히 좋지 않은 경우입니다.
또 하나 주의해야 하는 것이..
실루엣 계수가 무조건 크다고 해서 "오.. 대박"할 수도 없는 게
개별 군집의 실루엣 계수가 높게 나왔지만, 나머지 다른 군집들이 완전 말 그대로 망해버리는 경우가 있습니다. 평균의 함정에 빠져버릴 수 있는 것이죠.
이러면 평균값이 어느 정도 괜찮게 나올 수 있기 때문에.. 주의가 필요합니다. 예를 들어드리면,
이런 식이면, 파란색 군집의 실루엣 계수는 매우 높게, 잘 나올 것입니다.
그러나 주황색 부분의 군집들은 실루엣 계수가 나쁘게 나오게 나오겠죠.
이들의 평균을 구해보면 그럭저럭 꽤 괜찮은 실루엣 계수가 나와버릴 것입니다.
이런 경우가 있을 수 있기 때문에, 이 점을 유념한 채로 계수를 잘 봐야한다~~ 는 것입니다!
이러한 점때문에, 저는 실루엣 계수만을 이용한다기 보다는, 실루엣 계수와 위에서 했던 시각화 기법을 동시에 활용해서 판단합니다 ㅎㅎ 그게 다른 사람들을 설득할 때도 더 좋게 작용했던 것같아요!
🚩심화 문제🚩
K-Means는 각 데이터포인트들 간의 거리를 기반으로 군집을 형성합니다. 그러나 만약 아래와 같은 데이터에도 K-Means가 최선이라고 할 수 있을까요?
만약 K-Means를 적용하면 아래와 같은 결과가 나옵니다.
어... 잘 된 거 같지는 않죠? 위와 같은 데이터 분포에서 거리 기반의 알고리즘을 적용하면 제대로된 군집화가 이루어지지 않습니다. 그럼 어떻게 해야할까요?
거리 기반 외의 다른 군집화 방법이 필요합니다. 분량상 이 컨텐츠에서 코드까지 다뤄보지는 않을 거예요! 다만 알아두시면 군집화 작업이 필요하실 때 분명 유용하게 사용하실 수 있을 거예요.
수많은 군집화 기법 중 아래의 기법에 대해 설명해주세요. 어떤 방식과 과정을 통해 이루어지는지 요약해주시면 됩니다!
DBSCAN
GMM
계층적 군집화
2-1 차원축소
데이터는 많을 수록 좋습니다. 그러나 데이터를 설명하는 Feature가 너무 다양한 경우엔 오히려 모델의 입장에선 부정적인 영향을 줄 수 있습니다. 데이터를 묘사하는 것을 Feature라고 한다면, 데이터를 묘사하는 것이 너무 많으니, 오히려 혼란을 초래한다는 것입니다.
이러는 경우, Feature를 효율적으로 줄일 수 있는 방법은 뭐가 있을까요? 차원축소기법에 대해 알아봅시다.
차원의 저주
차원의 저주란 데이터의 차원이 커질 수록 필요한 데이터의 수가 그만큼 증가하게 되고, 이에 따라 모델의 성능이 저하되는 현상을 말합니다.
또한 동시에 데이터 간의 거리가 벌어져 밀도가 희소해지는데(sparse), 이런 경우 거리에 기반한 알고리즘 성능이 매우 떨어지게 됩니다. 그림으로 보시죠!
위와 같이, 차원이 늘어나면 늘어날 수록 개별 데이터간 거리는 점점 멀어지는 것을 확인하실 수 있습니다. 이렇게 되면 거리에 기반한 알고리즘이 제 힘을 쓰기가 힘들겠죠?
그리고 피쳐가 많을 수록 피쳐가 다른 피쳐에 의해 설명 가능하게 되는 다중 공선성(Multicollinearity) 문제가 발생하게 될 가능성이 커지게 됩니다. 다중 공선성이라는 개념은 매우 중요합니다. Skill과 감을 잡는 데에는 사실 그렇게 주요하지 않지만, 더 엄밀하고 명확한 해석이 필요할 땐 중요하게 고려해야하는 요소이기 때문이죠. 우리는 일단 간단하게 익히는 것이 목표이기 때문에, 다중공선성에 대해 자세히 알고 넘어가진 않겠습니다.
어쨌든, 위와 같은 문제를 해결하기 위해 제시된 것이 바로 차원축소 입니다!
크게 2가지로 나뉘는데
1. Feature Selection
2. Feature Extraction
기법입니다. 1번 문제에서 이미 간단하게 개념을 보고 오셨으니 간단하게만 확인하고 넘어가겠습니다.
Feature Selection 은 말 그대로 필요한 피쳐만 선택하는 것입니다.
예를 들어, 어떤 데이터의 피쳐가
a,b,c,d,e,f,g 로 있을 때, 이 중 필요한 피쳐가 a,b 만 있으면 된다고 판단하면 그냥 a,b만 가져다가 쓰는 것이죠.
Feature Extraction 은 기존의 피쳐를 살짝 변형하면서 압축합니다. 피쳐 선택이 그냥 있는 것 "그대로" 골라오는 것이었다면, 피쳐 추출은 있는 것을 살짝 변형시키면서 압축을 시킵니다.
예를 들어, 어떤 데이터의 피쳐가
a,b,c,d,e,f,g로 이루어져 있을 때, 피쳐 추출을 하면 새로운 피쳐 A,B 로 이들을 압축하는 것이죠.
실생활에 가까운 예시를 들면, 학생을 평가할 때,
모의고사 성적, 내신, 수행평가, 수능, 봉사활동, 독서기록, 선생님 평가... 이런 다양한 피쳐들을
학업성취도, 커뮤니케이션 능력과 같은 피쳐들로 압축이 가능하다는 것이죠.
이런 식으로 피쳐 추출을 진행하게 되면 장점이, 새로운 의미를 도출해낼 수 있음을 의미합니다.
압축 되기 전엔 몰랐는데 압축되고 나니, 비로소 새로운 잠재적인 의미가 눈에 보인다는 것이죠. 이런 잠재적인 요소(Latent Factor)를 뽑아낼 수 있다는 장점 덕분에, 많이 사용되는 것이구요.
이 Latent Factor의 개념은 딥러닝에서도 매우 중요하게 작용합니다. 수많은 정보를 적절하게 요약하는 것. 딱 봐도 사용처가 매우 많을 것같지 않나요? ㅎㅎ
오늘 우리는 이 중 Feature Extraction 기법의 대표주자인 PCA를 사용하는 방법 대해 알아보도록 하겠습니다. PCA를 이해하려면, 공분산, 고유벡터, 고유값에 대한 개념을 알고 계셔야해요! 분량상, PCA에 대한 개념 이해는 한 마디로 요약하면
n_clusters 인수는 k-means의 k를 의미하는 군집형성의 개수를 뜻한다. n_jobs는 scikit-learn의 기본적인 병렬처리로 내부적으로 멀티프로세스를 사용하는 것이다. 만약 CPU 코어의 수가 충분하다면 n_jobs를 늘릴수록 속도가 증가한다. random_state를 통해서 난수를 고정한다.
make_blobs
make_blobs 함수는 등방성 가우시안 정규분포를 이용해 가상 데이터를 생성한다. 이 때 등방성이라는 말은 모든 방향으로 같은 성질을 가진다는 뜻이다. 다음 데이터 생성 코드의 결과를 보면 make_classification 함수로 만든 가상데이터와 모양이 다른 것을 확인 할 수 있다. make_blobs는 보통 클러스링용 가상데이터를 생성하는데 사용한다. make_blobs 함수의 인수와 반환값은 다음과 같다.
인수:
n_samples : 표본 데이터의 수, 디폴트 100
n_features : 독립 변수의 수, 디폴트 20
centers : 생성할 클러스터의 수 혹은 중심, [n_centers, n_features] 크기의 배열. 디폴트 3
unique 내에 리스트, np.array 자료를 넣어주면 된다. 배열의 고유한 원소들을 모은 뒤, 1차원 shape으로 변환하고 정렬한 결과를 반환한다. unique의 axis 옵션을 통해서 행이나 열 기준의 블록을 단위로 고유한 배열들의 집합을 구할 수 있다. numpy의 unique 함수에서는 각 고유 원소가 처음 등장한 위치인 index 정보와 각 값이 몇 번째 고유 원소에 매칭되는지에 대한 inverse 정보, 그리고 각 고유 원소가 등장한 총 횟수를 나타내는 counts 정보를 추가로 받을 수 있다. 각각 return_index, return_inverse, return_counts 인자를 True로 설정하면 튜플 형태로 unique 결과와 함께 위 정보들을 추가로 받는 것이 가능하다.