Vectorstore는 임베딩된 벡터를 저장하는 말그대로 벡터 저장소이다.

Vectorstore의 종류

Vector store의 종류는 5가지인데 그 중에서 Pure vector databases와 Vector libraries에 집중하면 된다.
Pure database는 데이터베이스 안에 벡터값만 저장할 수 있다. 이 중에서 Pinecone, qdrant Chroma가 대표적이다.
Vector library중 FAISS는 페이스북에서 만든 AI semantic search tool로 가장 많이 쓰인다.
Pure vector database(PVD)와 Vector library(VL)의 차이점은 PVD는 일반적인 DB처럼 CRUD 기능이 제공된다.
반면 VL은 벡터 유사도를 구하는데 특화되어있는 툴이다. FAISS의 경우 벡터 유사도도 구해주고 벡터를 저장하는 역할도 한다.
근데 아무래도 PVD에 비해서 DB로써의 기능은 빈약하다.그리고 유지보수하기도 어렵다.
무료로 사용하고 싶으면 Chroma, 유료로 여러 기능을 사용하고 싶으면 Pinecone, Weaviate를 사용한다.
실습
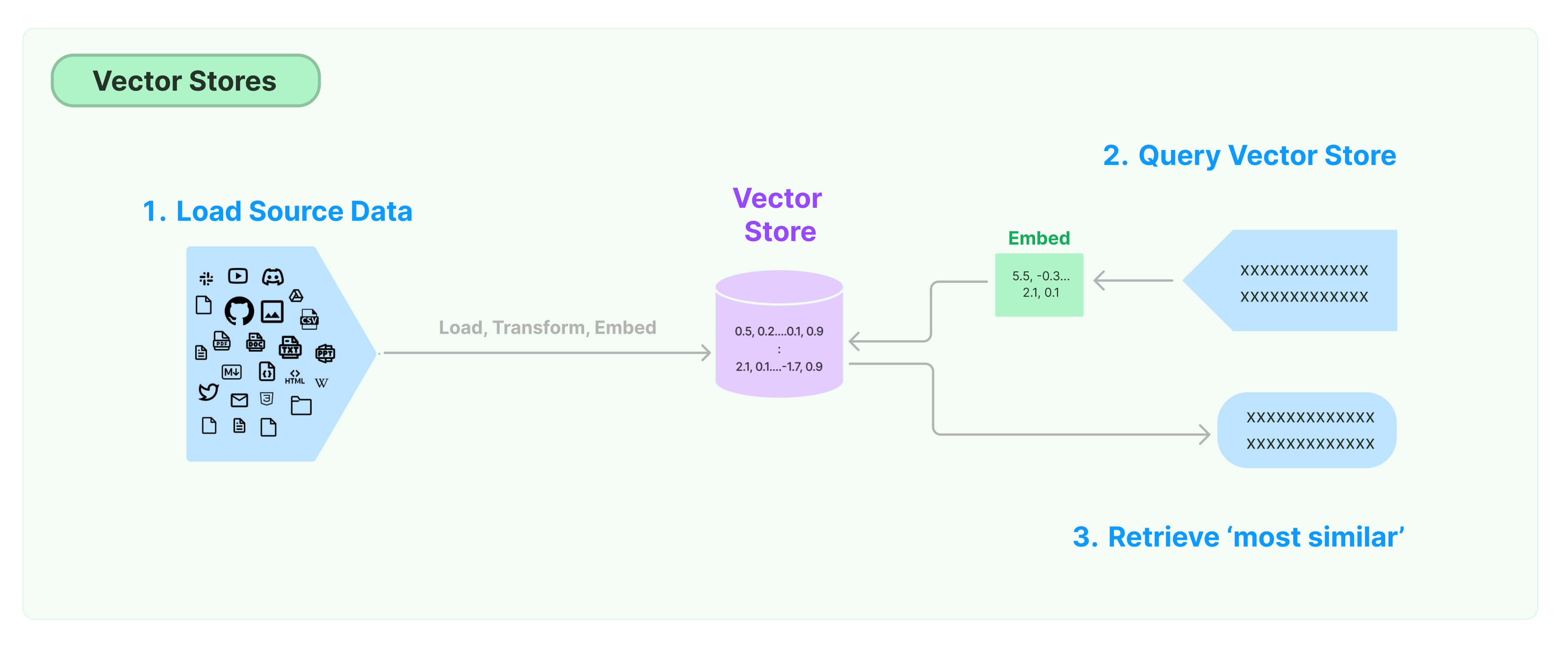
VectorStore는 자연어 --> 숫자 처리한 후 이들을 저장하는 벡터 저장소입니다.
벡터 저장소는 임베딩된 데이터를 인덱싱하여, input으로 받아들이는 query와의 유사도를 빠르게 출력합니다.
대표적으로 FAISS, Chroma가 존재합니다.
Chroma
대표적인 오픈소스 벡터 저장소
기본적으로 VectorStore는 벡터를 일시적으로 저장합니다. 텍스트와 임베딩 함수를 지정하여 from_documents() 함수에 보내면, 지정된 임베딩 함수를 통해 텍스트를 벡터로 변환하고, 이를 임시 db로 생성합니다.
그리고 similarity_search() 함수에 쿼리를 지정해주면 이를 바탕으로 가장 벡터 유사도가 높은 벡터를 찾고 이를 자연어 형태로 출력합니다.
!pip install chromadb tiktoken transformers sentence_transformers langchain pypdfimport tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
tokenizer = tiktoken.get_encoding("cl100k_base")
def tiktoken_len(text):
tokens = tokenizer.encode(text)
return len(tokens)from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import PyPDFLoader
# laod the document and split it into chunks
loader = PyPDFLoader("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
# split it into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0, length_function = tiktoken_len)
docs = text_splitter.split_documents(pages)
#create the open-source embedding function
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device':'cpu'}
encode_kwargs = {'normalize_embeddings':True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)# load it into Chroma
db = Chroma.from_documents(docs,hf)
# query it
query = "6대 먹거리 산업은?"
db_sim = db.similarity_search(query)
# print results
print(db_sim[0].page_content)db_sim- 분할한 문서 docs를 huggingface 모델 hf로 임베딩 벡터로 바꿔서 Chroma 벡터 디비에 저장한다.
- 질문을 넣어서 이것과 관련된 문장이 db에 무엇이 있는지 확인하고 docs에 저장한다.
- 가장 유사도가 높은 내용이 무엇인지 출력한 것.
tiktoken_len(db_sim[0].page_content)
그런데, 대부분의 경우에서는 내가 활용하고자 하는 문서를 나만의 디스크에 저장하고 필요할 때마다 호출해야 합니다. persist() 함수를 통해 벡터저장소를 로컬 저장하고, Chroma 객체를 선언할 때 로컬 저장소 경로를 지정하여 필요할 때 다시 불러올 수 있습니다.
# save to disk
db2 = Chroma.from_documents(docs,hf,persist_directory="./chroma_db")
db_sim = db2.similarity_search(query)# load from disk
db3 = Chroma(persist_directory="./chroma_db",embedding_function = hf)
db_sim = db3.similarity_search(query)
print(db_sim)
print(db_sim[3].page_content)쿼리와 유사한 문서(청크)를 불러올 때, 유사도를 함께 제공하는 함수 similarity_search_with_score()를 제공합니다. 이를 통해서 내가 얻은 유사한 문장들의 유사도를 비교할 수 있으며, 특정 유사도 이상의 문서만 출력하도록 하는 등 다양한 활용이 가능합니다.
#k값은 유사도 높은 문서 개수
db_sim = db3.similarity_search_with_relevance_scores(query,k=4)
print("가장 유사한 문서:\n\n {}\n\n".format(db_sim[3][0].page_content))
print("문서 유사도:\n {}".format(db_sim[3][1]))FAISS
Facebook AI 유사성 검색(Faiss)은 고밀도 벡터의 효율적인 유사성 검색 및 클러스터링을 위한 라이브러리입니다. 여기에는 모든 크기의 벡터 집합에서 검색하는 알고리즘이 포함되어 있으며, RAM에 맞지 않을 수 있는 벡터까지 검색할 수 있습니다. 또한 평가 및 매개변수 조정을 위한 지원 코드도 포함되어 있습니다.
!pip install faiss-cpufrom langchain.vectorstores import FAISSloader = PyPDFLoader("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
#split it into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size= 500,chunk_overlap=0,length_function = tiktoken_len)
docs = text_splitter.split_documents(pages)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
model_kwargs = {'device':'cpu'}
encode_kwargs = {'normalize_embeddings':True}
ko = HuggingFaceEmbeddings(
model_name = model_name,
model_kwargs = model_kwargs,
encode_kwargs = encode_kwargs
)db = FAISS.from_documents(docs,ko)query = "인공지능 산업구조는 어떻게 구성되어있어?"
docs = db.similarity_search(query)
print(docs[0].page_content)docs_and_scores = db.similarity_search_with_score(query)
docs_and_scores- similarity_search_with_relevance_score : 점수가 높을수록 유사도가 높음
- similarity_search_with_score : 벡터간의 거리가 score로 출력됨. 따라서, 점수가 낮을 수록 유사도는 높음
db.save_local("faiss_index")
new_db = FAISS.load_local("faiss_index", ko, allow_dangerous_deserialization=True)
query = "인공지능 산업구조는 어떻게 구성되어있어?"
docs = new_db.similarity_search_with_relevance_scores(query,k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{0}번째 유사 문서 유사도 \n{1}".format(i+1,round(docs[i][1],2)))
print("-"*100)
print(docs[i][0].page_content)
print("\n")
print(docs[i][0].metadata)
print("-"*100)query = "5G 이동통신 시스템은?"
docs = new_db.max_marginal_relevance_search(query,k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"*100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"*100)
print("\n\n")- similarity search는 유사도 기준으로 가장 유사도가 높은 문서들을 반환해준다.
- max_marginal_relevance_search는 가장 유사도가 높은 문서도 내놓지만 그 와중에 뽑히는 문서들의 다양성을 고려함.
query = "인공지능 산업구조는 어떻게 구성되어있어?" docs = new_db.max_marginal_relevance_search(query,k=3)
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"_100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"_100)
print("\n\n")
```python
query = "인공지능 산업구조는 어떻게 구성되어있어?"
docs = new_db.max_marginal_relevance_search(query,k=3,fetch_k = 10, lambda_mult = 0.3) # 최대한 다양성(lambda_mult)을 확보하면서 높은 유사도의 문서를 추출
# 가장 유사한 문서를 내놓기도 하지만
# 상위 문서를 보여줄때 다른 문서를 최대한 찾아서 3개를 반환할 수 있도록 (3가지 문서가 최대한 베타적이도록 = 다양성을 보존하며 유사하도록)
# fetch_k : 총 몇개의 문서에서 다양성을 보존한 상태로 n개를 뽑을지 / e.g. fetch_k:20 = 20개의 유사도 상위 문서 중 다양성이 유지되도록 n개를 뽑도록
# lambda_mult: 다양성 or 유사도 에 대한 조정
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"*100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"*100)
print("\n\n")query = "MTEB이 무엇인가요?"
docs = new_db.max_marginal_relevance_search(query,k=3,fetch_k = 10, lambda_mult = 0.3) # 최대한 다양성(lambda_mult)을 확보하면서 높은 유사도의 문서를 추출
# 가장 유사한 문서를 내놓기도 하지만
# 상위 문서를 보여줄때 다른 문서를 최대한 찾아서 3개를 반환할 수 있도록 (3가지 문서가 최대한 베타적이도록 = 다양성을 보존하며 유사하도록)
# fetch_k : 총 몇개의 문서에서 다양성을 보존한 상태로 n개를 뽑을지 / e.g. fetch_k:20 = 20개의 유사도 상위 문서 중 다양성이 유지되도록 n개를 뽑도록
# lambda_mult: 다양성 or 유사도 에 대한 조정
print("질문: {} \n".format(query))
for i in range(len(docs)):
print("{}번째 유사 문서:".format(i+1))
print("-"*100)
print(docs[i].page_content)
print("\n")
print(docs[i].metadata)
print("-"*100)
print("\n\n")Reference
모두의 AI 유튜브 채널[https://www.youtube.com/@AI-km1yn]
'인공지능 > RAG' 카테고리의 다른 글
| Langchain - ChatPromptTemplate (0) | 2024.05.23 |
|---|---|
| LangChain (9) Retrieval - Retriever (0) | 2024.04.08 |
| LangChain (7) Retrieval - Text Embeddings (0) | 2024.04.08 |
| LangChain (6) Retrieval - Text Splitters (0) | 2024.04.08 |
| Knowledge Distillation (0) | 2024.04.06 |