인공지능/RAG
LangChain (11) 오픈소스 LLM으로 RAG 구현
BangPro
2024. 6. 4. 13:42
728x90
오픈소스 LLM의 필요성
- 비용 : API 호출시마다 비용 발생
- 보안 : 기업 정보 유출 우려
- 안정성 : API를 관리하는 회사에서 문제가 생기면 서비스 제공이 불가
한국의 오픈소스 LLM
업스테이지와 NIA가 주관하여 한국어 오픈소스 LLM 리더보드 운영중. 이 리더보드를 통해서 최신 오픈소스 LLM들의 성능 비교하고 사용 가능
오픈 소스 LLM의 양자화(Quantization)
컴퓨팅 리소스 부담을 줄이기 위해 양자화를 통해 경량화한 모델을 많이 활용
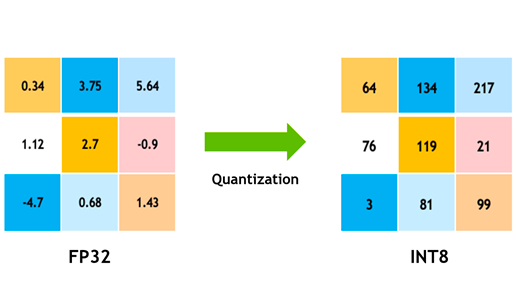
모델 양자화를 통해 가중치 정확도(소수점)을 줄여서 계산량과 저장해야하는 정보를 줄인다.
실습
1단계 - LLM 양자화에 필요한 패키지 설치
- bitsandbytes: Bitsandbytes는 CUDA 사용자 정의 함수, 특히 8비트 최적화 프로그램, 행렬 곱셈(LLM.int8()) 및 양자화 함수에 대한 경량 래퍼
- PEFT(Parameter-Efficient Fine-Tuning): 모델의 모든 매개변수를 미세 조정하지 않고도 사전 훈련된 PLM(언어 모델)을 다양한 다운스트림 애플리케이션에 효율적으로 적용 가능
- accelerate: PyTorch 모델을 더 쉽게 여러 컴퓨터나 GPU에서 사용할 수 있게 해주는 도구
#양자화에 필요한 패키지 설치
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git2단계 - 트랜스포머에서 BitsandBytesConfig를 통해 양자화 매개변수 정의하기
- load_in_4bit=True: 모델을 4비트 정밀도로 변환하고 로드하도록 지정
- bnb_4bit_use_double_quant=True: 메모리 효율을 높이기 위해 중첩 양자화를 사용하여 추론 및 학습
- bnd_4bit_quant_type="nf4": 4비트 통합에는 2가지 양자화 유형인 FP4와 NF4가 제공됨. NF4 dtype은 Normal Float 4를 나타내며 QLoRA 백서에 소개되어 있습니다. 기본적으로 FP4 양자화 사용
- bnb_4bit_compute_dype=torch.bfloat16: 계산 중 사용할 dtype을 변경하는 데 사용되는 계산 dtype. 기본적으로 계산 dtype은 float32로 설정되어 있지만 계산 속도를 높이기 위해 bf16으로 설정 가능
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)3단계 - 경량화 모델 로드하기
이제 모델 ID를 지정한 다음 이전에 정의한 양자화 구성으로 로드합니다.
model_id = "kyujinpy/Ko-PlatYi-6B"
tokenizer=AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,quantization_config=bnb_config,device_map="auto")- AutoTokenizer.from_pretrained :
model_id에서 사용된 토크나이저를 자동으로 가져온다. - AutoModelForCausalLM.from_pretrained :
model_id에서 사용된 언어모델을 자동으로 가져온다.- quantization_config : 경량화 기법 어떻게 할건지 정의하는 부분. 우리는 위에서 정의한 BitsAndBytes config를 전달한다.
- device_map : auto로해서 어떤 gpu에서 돌아갈지 자동으로 설정해준다.
print(model)- LLama 기반 모델
- (embed_tokens): Embedding(78464, 4096, padding_idx=0) 부분을 살펴보면 78464 토큰이 들어오면 4096차원으로 임베딩 시킨다는 뜻이다.
- 모델을 print를 주는 이유는 양자화 잘 되었는지 확인하기 위해서이다.
- Attention 부분에 Linear4bit으로 돼있으면 4bit로 양자화가 잘 된거다.
4단계 - 잘 실행되는지 확인
device = "cuda:0"
messages = [
{"role":"user","content":"은행의 기준 금리에 대해서 설명해줘"}
]
encodes = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodes.to(device)
generated_ids = model.generate(model_inputs,max_new_tokens=1000,do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])- device를 cuda 첫번째 걸로 정의(gpu로 설정한다고 생각하자)
- tokenizer의 apply_chat_template을 통해 messages를 토크나이저에 넣고 인코딩한다.
- return_tensors = 'pt'로 설정해서 pytorch tensor 형식으로 메시지를 변환해준다.
- 인코딩한 값을 device(gpu)에 넣는다.
- 모델의 generate 함수를 통해서 model_input을 넣어서 결과를 출력받는다
- 최대 토큰 설정
- sampling은 뭐지?
- 토크나이저의 batch_decode를 통해서 LLM이 생성한 임베딩을 자연어로 변환해준다.
RAG 시스템 구현
!pip -q install langchain pypdf chromadb sentence-transformers faiss-cpufrom langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from transformers import pipeline
from langchain.chains import LLMChain
text_generation_pipeline = pipeline(
model = model,
tokenizer=tokenizer,
task="text-generation",
temperature=0.2,
return_full_text = True,
max_new_tokens=300,
)
prompt_template = """
### [INST]
Instruction: Answer the question based on your bank economy knowledge.
Here is context to help:
{context}
### QUESTION:
{question}
[/INST]
"""
koplatyi_llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
#Create Prompt from Prompt Template
prompt = PromptTemplate(
input_variables=["context","question"],
template=prompt_template,
)
#create llm chain
llm_chain = LLMChain(llm=koplatyi_llm,prompt=prompt)HuggingFacePipeline과LLMChain은 API를 통해서 답변을 얻으면 필요 없는 라이브러리- 모델에 질문을 하고 답변을 받는 일련의 과정을 pipeline을 통해서 수행
HuggingFacePipeline을 사용하는 이유는 langchain과 결합할때 허깅페이스 파이프라인과 결합하는게 더 편해서이다.- LLMChain을 통해서 어떤 prompt template으로 어떤 llm을 돌리냐만 정의해주면 chain이 완성된다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.schema.runnable import RunnablePassthroughloader = PyPDFLoader("/content/drive/MyDrive/코딩/LangChain 실습(모두의AI)/data/[이슈리포트 2022-2호] 혁신성장 정책금융 동향.pdf")
pages = loader.load_and_split()
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap=50)
texts = text_splitter.split_documents(pages)
from langchain.embeddings import HuggingFaceEmbeddings
model_name = "jhgan/ko-sbert-nli"
encode_kwargs={"normalize_embeddings":True}
hf = HuggingFaceEmbeddings(
model_name = model_name,
encode_kwargs=encode_kwargs
)
db = FAISS.from_documents(texts,hf)
retriever = db.as_retriever(
search_type = "similarity",
search_kwargs={'k':3}
)rag_chain = (
{"context":retriever,"question":RunnablePassthrough()}
| llm_chain
)rag_chain : rag_chain에 들어오는 값을 question으로 삼아서 해당 질문을 토대로 retriever를 통해서 context를 넣을 내용을 가져온다.
그리고 llm_chain으로 들어오는 질문과 context를 넣어서 답변을 생성한다.
import warnings
warnings.filterwarnings('ignore')result = rag_chain.invoke("혁신성장 정책 금융에서 인공지능이 중요한가?")
for i in result['context']:
print(f"주어진 근거: {i.page_content} / 출처: {i.metadata['source']} - {i.metadata['page']} \n\n")
print(f"\n답변:{result['text']}")